
PostLN, PreLN and ResiDual Transformers
Eliminating the need for warm-up stage for training transformers

In the previous post, we delved into the transformer architecture in details. As a brief recap, the original transformer model is composed of a stack of encoders and a stack of decoder layers. The encoders and decoders are interconnected with cross-attention. Focusing on the encoders, each encoder layer is composed of two sub-blocks: 1) a Multi-Head Attention (MHA) block, and 2) a Feed-Forward Network (FFN). Furthermore, training the original transformer requires a warm-up stage, that is, we have to start training with a very small learning rate, and gradually increase the learning rate in the warm-up stage. Once we reach the maximum LR, then we can use any conventional learning scheduler as we wish.
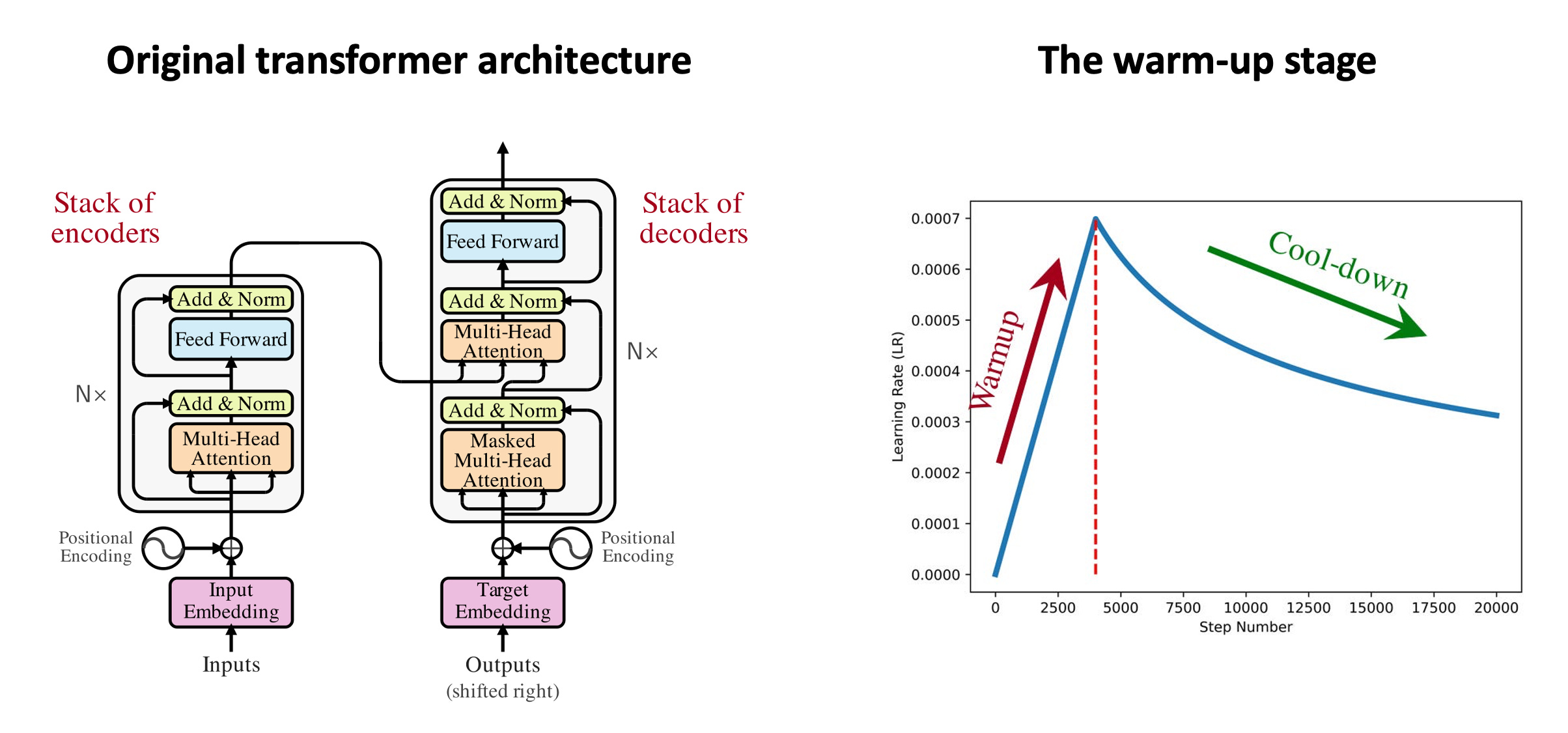
The warm-up stage is one of the main drawbacks of the original transformer architecture, due to the following reasons:
Starting the training with small learning rate slows down the training process.
Warm-up stage requires additional hyperparamaters such as the number of warm-up steps, and maximum leanring rate.
In this post, we delve into why the original transformer requires warm-up stage, and what are alternative architectures that do not need the warm-up stage.
Training stability of the original transformer
In the original transformer, the LayerNorm is placed after the residual connection (Add & Norm). This placement is called PostLN architecture, since the LayerNorm (LN) is placed after the MHA layer and outside the residual block. A simplified diagram of the MHA sub-block is shown below:

As you can see, this architecture suffers from a major limitation, which is there is no un-interruptable pathway from the output layer to the input layer, so the gradients cannot flow directly, leading to vanishing gradients for the initial layers. In order to prevent the vanishing gradients, one idea is to use a larger LR, but that causes exploding gradients in the layers near the output.
As a practical solution, we have to start training with a very small learning rate, and as the training progresses, the gradients become more stable, and there is no need to keep the inital small learning rate. Therefore, the authors of the original transformer (“Attention Is All You Need”) decided to use a leanring-rate warm-up stage to resolve these issues.

Alternative architectures
The issues in PostLN architecture is due to the lack of a direct pathway for gradients to flow through the layers. However, with a rather simple idea, we can modify the architecture such that the gradients can flow through skip-connections around each block, from the last layer all the way to the initial layer. To do this, we can move the LayerNorm from outside the residual block to be placed inside the residual block as shown below:

As you can see, in the PreLN architecture, the gradients can flow back from later n+1 to layer n without any interruption. This modification resolves the graident issues:
Gradients are well-behaved in PreLN architecture
No need for warm-up stage
Fewer hyper-parameters
However, the PreLN architecture has some other drawbacks:
Representation collapse: the early normalization as done in PreLN transformer homogenizes the internal representaitons and limits the diversity. Therefore, the model's internal representations become less diverse or informative.
Poor preformance: when a PostLN transformer is successfully trained, its performance is often higher than the PreLN architecture.
ResiDual transformer
As we have seen so far, the PostLN and PreLN both have their own issues. PostLN suffers from gradient vanishing and gradient exploding issues, while PreLN suffers from representation collapse. Now, the question is can we have an architecture that combine advantages of both PostLN and PreLN without sufering from their issue. ResiDual is a variant transformer architecture that tries to achieve exactly that goal.

The ResiDual architecture has two parallel branches as shown in the figure above. The left branch is similar to PostLN architecture, where the LayerNorm is placed outside the residual block. This placement of LayerNorm after the residual block prevents the homogenization of the internal representation that lead to reprsentation collapse issue in PreLN architecture.
The right branch in ResiDual architecture takes the output of MHA and add that to the representations from the previous branch. The right branch is responsible for the easy passage of the gradients during back-propagation. Therefore, the ResiDual architecture takes best of the both worlds.
Summary
In this article, we delved into some of the limitations of the original transformer due to gradient vanishing and gradient exploding issues. The original transformer uses a PostLN architecture, which does not allow gradients to flow backward easily, as they are interrupted by the LayerNorm. Then, we delved into alternative architectures namely PreLN and ResiDual. The PreLN moves the LayerNorm inside the residual block, which resolves the graident issues but brings a new problem, that is representation collapse. On the other hand, ResiDual uses two parallerl branches to take advantages of both architectures.

References
“Attention Is All You Need”, Vaswani et al, 2017, https://arxiv.org/pdf/1706.03762.pdf
“Learning Deep Transformer Models for Machine Translation”, Wang et al. 2019, https://arxiv.org/pdf/1906.01787.pdf
“On Layer Normalization in the Transformer Architecture”, Xiong ey al. 2020, https://arxiv.org/pdf/2002.04745.pdf
“ResiDual: Transformer with Dual Residual Connections”, Xie et al., 2023, https://arxiv.org/pdf/2304.14802.pdf